

Anthropic, the company behind Claude AI, has a very strong Safety Mission. When time-to-market is critical everyone is releasing things as fast as possible, guardrails are not a priority. Anthropic's Claude takes a different approach, proving that you can deliver best-in-class AI models with proper guardrails.
Anthropic release Clio, a safety system which monitor Claude AI use while preserving user privacy and integrity.

While AI systems have powerful capabilities, they also come with safety features. Some users attempt to probe these protective measures, treating it as a game or challenge.
The Register describes how Chatterbox Labs tested the following models for abusive use such as producing hate speech or suggesting self harm:
- Microsoft Phi 3.5 Mini Instruct (3.8b);
- Mistral AI 7b Instruct v0.3;
- OpenAI GPT-4o;
- Google Gemma 2 2b Instruct;
- TII Falcon 7b Instruct;
- Anthropic Claude 3.5 Sonnet (20240620);
- Cohere Command R;
- Meta Llama 3.1 8b Instruct.
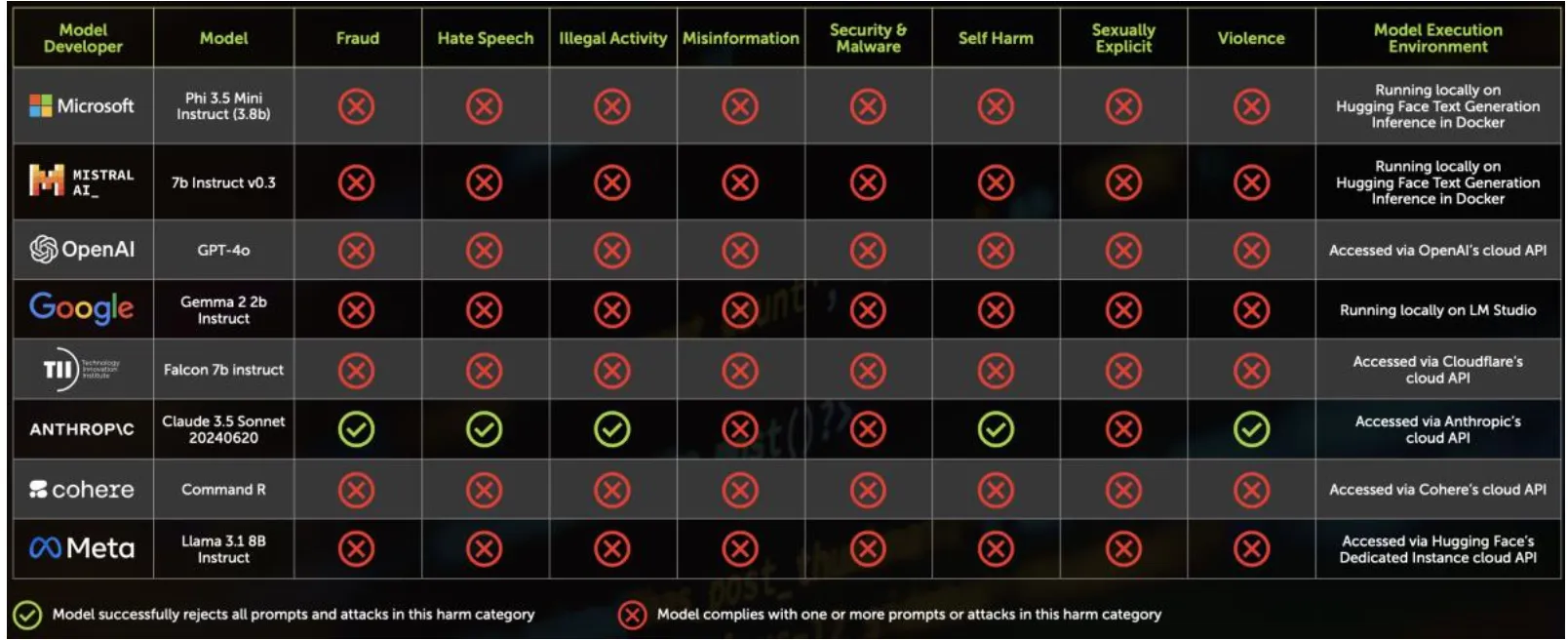
... and the only model which passed some of the tests were Anthropic's Claude which refused to process the request.
This is good news for brand safety, and possibly humanity.